4W - EKS 모니터링과 관측 가능성
개요
이번 글에서는 EKS를 모니터링하는 방법과 관련한 세팅을 해본다.
주로 AWS에서 지원하는 모니터링 솔루션들을 알아보고, 다음 글에서 오픈소스 모니터링 툴인 프로메테우스 스택을 본다.
사전 지식
관측 가능성
Observability, 관측가능성이란 프로그램 실행, 모듈의 내부 상태, 컴포넌트 간 통신에 대한 데이터를 수집하는 기능으로 정의된다.[1]
이것은 시스템의 기능 중 하나로 관리자가 잘 볼 수 있도록 필요한 메트릭과 각종 정보를 수집해서 내어주는 기능을 말한다.
그래서 이 개념은 사실 관리자의 행위인 모니터링과 대비되는 개념이 아니다.
이 개념이 화두가 된 이유는 복잡해진 현대 시스템 아키텍쳐에서는 관리자가 수동적으로 모니터링만 하는 상태에서 원하는 수준의 관찰을 하는 것이 어려워졌고, 이에 따라 관련 툴을 설치하거나 세팅을 하는 등 추가적인 운영 요소가 생기게 되었음을 강조하기 위해서이다.
자세한 건 문서를 참조하고, 관측 가능성에서는 크게 3가지 유형의 데이터를 지정한다.
Metric
시스템의 특정 시간을 나타내는 수치값이다.
메모리 사용량, 초당 http 요청량, 데이터베이스 사이즈 등이 여기에 해당한다.
Log
자유롭게 생성되는 각종 텍스트 데이터를 말한다.
이 개념은 사실 굉장히 포괄적인데, 어떤 데이터를 담고 있는 흔적들이라고만 이해해도 무방하다.
프로세스의 표준 출력, 디비 접속 기록 로그 파일 등이 전부 로그에 해당한다.
Trace
트래픽, 혹은 프로세스의 흐름을 말한다.
분산 아키텍쳐에서는 하나의 프로세스가 모든 로직을 담당하지 않는 경우가 왕왕 있다.
가령 어떤 유저가 자신의 글을 확인하는 api를 요청했다고 해보자.
어떤 아키텍처에서는 먼저 게이트웨이에 이 요청이 온 후에 인증 서버, 인가 서버를 거쳐 유저의 요청을 허용할지 말지를 정한다.
이후에는 디비와 통신하는 서버로 요청이 들어가고, 샤딩된 디비에서는 어떤 디비에서 데이터를 가져올지 정한다.
이런 식의 일련의 트래픽이 발생할 때, 정확하게 어떤 프로세스가 어떤 요청을 받았는지 추적하고 이를 측정하는 것이 바로 trace이다.
실습 진행
콘솔을 통한 모니터링

EKS 콘솔에서 기본적인 클러스터 상황을 확인할 수 있다.

한 리소스에 들어가면 또 이렇게 각종 정보들이 나오기 때문에 나름 편하게 모니터링을 하는데 도움을 준다.

참고로 콘솔에서 클러스터 정보를 확인할 수 있는 이유는 콘솔 세션에 대해 insight 정책이 붙었기 때문이다.
컨트롤 플레인 로깅
컨트롤 플레인은 사용자가 관리하는 영역이 아니기 때문에 구체적으로 어떻게 모니터링해야 할지 감을 잡기 어렵다.
그렇지만 또 안할 수도 없는 노릇인 게, 임의의 사용자가 접속한다던가, 누군가 클러스터 조작을 못하고 있다면 왜 못하고 있는지 이유를 알아낼 필요가 있다.
이를 위해 컨트롤 플레인에서 발생하는 각종 로그 정보를 수집하도록 설정하는 것이 가능하다.
테라폼 세팅
create_cloudwatch_log_group = true
cluster_enabled_log_types = [ "audit", "api", "authenticator", "scheduler", "controllerManager"]
테라폼 eks 모듈에서는 굉장히 간단하게 세팅이 가능하다.
이렇게 5개로 분류되는 로그들을 남길 수 있다.
근데, 여태까지 해본 바로는 이 기능을 false로 해둬도 로깅이 활성화된다..
확인

그러면 클라우드워치에 이렇게 기록이 남게 된다.
이렇게 클라우드워치로 보는 것도, 저장하는 것도 다 비용이라, 필요한 정보만 적절히 로깅하는 것이 중요하다.

참고로 많이 경험해보진 않아서 잘은 모르겠으나, 이 정도의 비용이 발생한다는 것 같다.
각 분류 그룹이 어떤 그룹을 담는지 확인해보자.

authenticator에는 EKS 클러스터에서 이뤄지는 IAM 자격증명과 관련된 로그가 담긴다.

apiserver에는 그냥 api 서버 컨테이너에 남는 로그가 보인다.
API 서버 차원에서 확인해야 하는, CRD 등록 여부나 관련 정보는 여기에서 확인하면 된다.

audit에는 api 서버가 남기는 audit 정보가 보인다.
클러스터 내부에서 일어나는 인증 인가와 조작에 대한 정보는 여기에서 확인하면 된다.
보안의 관점에서 로깅이 필요하다면 이 로그는 매우 유의미하다.
어떤 account가 어떤 동작을 했는지 모든 기록이 남기 때문이다.
조금 아쉽게 느껴지는 것은 audit을 어떻게 남길지 커스텀하는 방법이 없는 것.[2]
또한 내 마음대로 규칙을 지정할 수 없으니 여기에는 불필요하다고 느낄 만한 정보도 담겨버릴 것이고, 금새 크기도 불어날 것이다.
여기에서도 비슷한 요청과 생각이 보인다.[3]

cloud controller manager의 로그도 확인할 수 있다.
서비스를 만들어도 이걸 활용할 일은 없을 것이고, 실질적으로 노드에 대한 정보 확인할 때나 쓸 텐데 그걸 또 로그로 확인할 필요도 없다고 생각한다.

scheduler의 정보도 남는데, 이건 어차피 이벤트로 정보가 거의 다 남기 때문에 이것도 돈 낭비일 것 같다.

마지막으로 controller manager 로그.
이것도 볼 일이 얼마나 있을까.. 싶긴 하다.
쿠버네티스에서는 코어 컴포넌트에서 에러를 일으킬 만한 동작들이 있다면 웬만해서는 미리 검증 에러를 내거나 이벤트로 표시를 해주기 때문에 이런 로그는 특정 상황이 아니라면 필요하진 않을 것 같다.
log insight 활용

클라우드 워치에서 조회되는 로그 그룹에 대해서 로그 인사이트 기능을 이용해 로그를 쿼리하는 것도 가능하다.
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc

간단하게 audit으로 어떤 유저가 많이 요청을 하는지 확인할 수 있다.

ELB 헬스체커가 많이 동작하는 게 보여서 확인해봤는데 헬스체크에 꽤나 많은 통신이 발생하고 있다.
ALB 컨트롤러에서 일으키는 요청이 아닐까 생각했는데, 컨트롤러가 설치되기 이전부터 발생한 요청이기에 컨트롤 플레인의 로드밸런서가 보내는 헬스체크 요청으로 보인다.

이 요청은 public-info-viewer라는 클러스터롤을 통해 허용되며, 인증되지 않은 유저가 접근할 수 있게 돼있다.

요컨대 아무런 인증 수단을 마련하지 않는 요청도 허용되고 있다는 말이다.
당연히 헬스체크야 긴밀하게 이뤄져야 한다고는 생각했지만, 1시간에 12000개가 생길 것이라곤 생각하지 못했다.
1분에 2000번의 헬스체크?
1초에 한번씩 각 노드가 api서버에 /livez /readyz를 날린다고 해보자.
나는 지금 노드가 3개 있고, 컨트롤 플레인 내부에서도 해당 요청을 날릴 수도 있으니 노드는 총 6개라 생각해보면 1분에 날아가는 요청 개수는 360개이다.
여기에 api 서버 앞단의 로드 밸런서가 날릴 요청까지도 생각해도 이게.. 1분에 2000번이 발생할 수가 있나?
또 어떤 컴포넌트가 api 서버 헬스체크를 수행할까?
잘 모르겠지만, 일단 이에 대한 로그를 남기면 비용이 커질 것 같다.
추가적으로 이 트래픽 비용도 사용자가 부담하는 거라면 상당히 부담될 것 같은데..
조금 더 알아봐야겠지만 불필요한 헬스체크가 일어나고 있는 것은 아닐까 우려된다.
CloudWatch Container Observability

클러스터 내부의 각종 어플리케이션과 노드의 정보를 모니터링할 때, cloudwatch container observability 애드온을 활용할 수 있다.[4]
이걸 세팅하면 cloudwatch agent 파드와 fluentbit 파드가 데몬셋으로 배포되면 각 노드의 메트릭과 로그를 수집하게 된다.
(fluent bit은 fluentd와 호환되면서 훨씬 가벼운 로그 수집기라고 한다.)

이렇다고 하는데, 깊게 공부하지는 않았다.
구체적으로 이 애드온은 다음의 세 가지 로그를 수집한다.
- 어플리케이션
- 노드에 저장되는 파드, 컨테이너에서 발생하는 로그를 수집한다.
- 노드
- journalctl 등으로 조회가능한 노드 자체에 대한 로그를 수집한다.
- 데이터 플레인
- kubelet, kube proxy등 워커 노드로서 발생하는 각종 로그를 수집한다.
테라폼 세팅
####################################################
##### Amazone CloudWatch Observability
####################################################
resource "aws_eks_addon" "cloudwatch_observability" {
cluster_name = module.eks.cluster_name
addon_name = "amazon-cloudwatch-observability"
addon_version = "v3.3.0-eksbuild.1"
resolve_conflicts_on_update = "PRESERVE"
configuration_values = jsonencode({
agent = {
mode = "daemonset"
}
})
service_account_role_arn = module.cco_irsa.iam_role_arn
}
module "cco_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "5.52.2"
role_name = "cco"
attach_cloudwatch_observability_policy = true
force_detach_policies = true
oidc_providers = {
eks = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["amazon-cloudwatch:cloudwatch-agent"]
}
}
}
여타 다른 애드온 설정해주듯이 설정을 해줬다.
configuration에서, 기본이 데몬셋이라 저렇게 설정할 필요는 없지만 statefuleset과 deployment도 사용할 수 있길래 그냥 신기해서 넣어봤다.
확인

세팅이 완료되면 amazon-cloudwatch라는 네임스페이스의 많은 리소스들이 배포된다.
k stern -n amazon-cloudwatch cloud

정책 구성도 완료됐다면 이런 식으로 뜬다.
만약 빨간색이 있다면 정책 설정 여부를 확인하자.

클라우드워치로 가보면 로그 그룹에 이렇게 세 항목이 추가된 것이 보인다.

제대로 설정이 완료되면 이렇게 cloudwatch container insight에서 모니터링이 가능해진다.
이전 실습 때 만들었던 클러스터가 아직도 표시가 되고 있는데, 이건 왜 이런지 잘 모르겠다.

이 친구는 꽤나 괜찮은 것 같은데, 클러스터에 대한 각종 정보를 간편하게 보는 것이 가능하다.

아래에 클러스터를 하나 특정해서 보면 내용물을 조금 더 구체적으로 확인할 수 잇다.
클러스터 별, 네임스페이스별, 파드별 등 다양한 관점에서 지표를 확인할 수 있어 매우 유용하다고 생각한다.
현재 사진은 클라우드워치 애드온 관련 네임스페이스 정보인데, 자원 사용량이 크지 않은 것이 보인다.

그나마 메모리 사용량이 1.4퍼인 파드 하나를 들어가서 봤는데.. 컨테이너가 68개..?라고 해서 순간 내 눈을 의심했다.
근데 상단에 뜨는 건 클러스터 전체 값인 듯하다.

맵 뷰를 누르면 이렇게 이쁘게 상관 관계를 볼 수 있다.
자원 사용량에 대한 종합적인 표시도 해주고 있어서 편리해보인다.
k -n amazon-cloudwatch get cm fluent-bit-config -o yaml

이 애드온 자체에 대한 로그에 대한 정보는 볼 수 없었는데, EKS 애드온 관련 컨테이너 로그들을 제외하고 있기 때문이다.

데이터 플레인 로그는 journal 등의 장소에서 담고 있다.
fluent bit은 이렇게 로그를 수집하고, 이것은 cloudwatch agent가 aws로 날려주게 될 것이다.
번외 - fluent bit의 보안 취약성에 대해
k -n amazon-cloudwatch get po fluent-bit-w268b -o yaml | yh
이 블로그[5]에서 fluentbit 컨테이너의 보안 취약점에 대해 이야기하는 부분을 확인해서 한번 확인해본다.

해당 글에서 포착한 내용에 따르면 루트 디렉토리에 도커 소켓까지 마운팅을 하고 있다.
이건 확실히 엄청난 위험성을 가지는 설정이기는 하다.

하지만 클러스터 1.31버전에서 사용하는 애드온 3.3.0 버전에서는 그런 문제를 수정한 것으로 보인다.

다만 내 소견으로, 문제가 있던 버전에서도 마운팅 시 readOnly 옵션이 부여되어있지 않았을까 한다.
이러면 최소한 해당 컨테이너에서의 write은 막히기에 당연한 설정이다.
여담으로, rercursiveReadOnly가 disabled된 것도 사실 위험할 수 있다.
E-파드 마운팅 recursiveReadOnly 참조.
kwatch로 간단하게 알림 받기
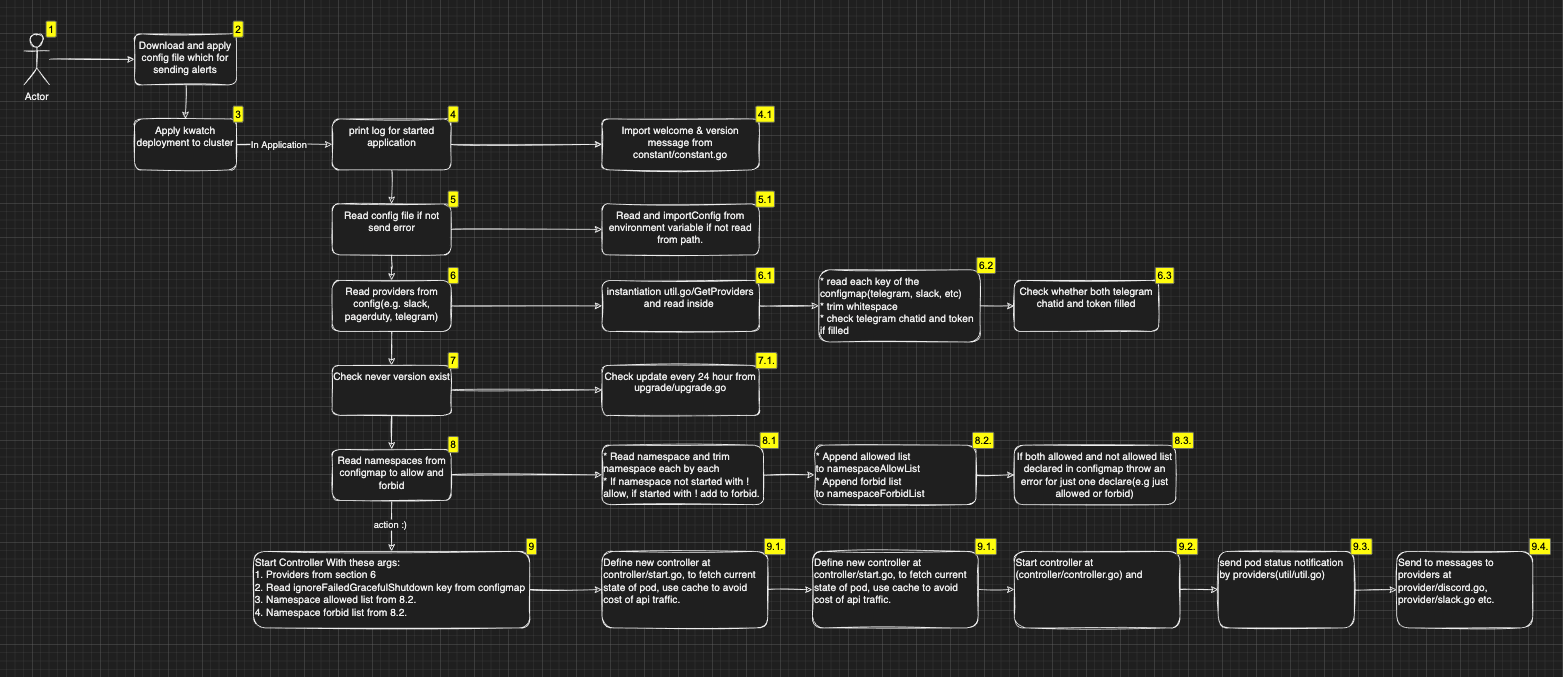
kwatch는 클러스터 내의 변화를 감지하고 어플리케이션의 문제가 발생했을 때 알람을 주는 간단한 툴이다.[6]
구조가 복잡하게 생긴 것 같지만, 실질 로직이 저게 전부라 오히려 사실 엄청 간단한 형식이라 볼 수 있다.
helm repo add kwatch https://kwatch.dev/charts
helm repo update
helm install kwatch kwatch/kwatch --version 0.10.1

배포는 간단한데, 여기에서 configmap에 대해서 설정해주면 된다.[7]
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
data:
config.yaml: |
alert:
discord:
webhook: https://discord.com/api/webhooks//-q-rp4vGiM7w-b-EO8wMOmuu2UvuXMu_nTE2xCT53T1_bfcas4gkOWf647IV
title: 왈왈
text: 박박

스터디 실습 때는 슬랙에 알림을 보냈는데, 나는 디스코드 방 하나 파서 날려본다.

아무렇게나 이미지를 잘못 설정한 파드를 만들었다.
제외할 Reason이나 네임스페이스도 따로 커스텀이 가능하다.
결론
컨트롤 플레인을 모니터링하기 위해서는 무조건 AWS의 솔루션을 사용해야만 한다.
이에 대한 자세한 커스텀을 지원하지 않기 때문에, 운영 간 비용이 많이 발생할 수 있다는 것을 주의해야 한다.
(E-api 서버 감사 정책을 설정하지 못하게 한 건 선 넘었다.)
데이터 플레인에 대해 AWS에서는 애드온으로 상당히 매력적인 애드온을 제공하고 있다.
설정도 매우 간단하기 때문에 전문적으로 SRE 팀을 운영하지 않는 운영 환경에서는 비용을 부담할 수 있다면 상당히 괜찮은 선택지로 보인다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | 1 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | 2 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | 3 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | 4 | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | 5 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | 6 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | 7 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | 8 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | 9 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | 10 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | 11 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | 12 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | 13 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | 14 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | 15 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | 16 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | 17 | published | 2025-03-22 |
| 7W - EKS Fargate | 18 | published | 2025-03-22 |
| 7W - EKS Automode | 19 | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | 20 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | 21 | published | 2025-03-30 |
| 8W - 아르고 CD | 22 | published | 2025-03-30 |
| 8W - CICD | 23 | published | 2025-03-30 |
| 9W - EKS 업그레이드 | 24 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | 25 | published | 2025-04-16 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-04-18 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-05-11 |
| 12W - VPC Lattice 기반 gateway api | 27 | published | 2025-04-27 |
관련 문서
| 이름 | noteType | created |
|---|